ReCAPTCHA's quality is going down?
.flickr-photo { border: solid 2px #666; } .flickr-frame { text-align: left; padding: 3px; } .flickr-caption { font-size: 10px; margin-top: 0px;color:#999; }
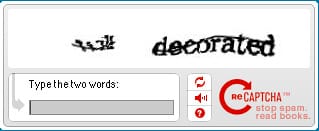
ReCAPTCHA's quality is going down, originally uploaded by mathowie.
Several months ago, we implemented ReCAPTCHA on MetaFilter contact forms, to thwart spammers. It's a good cause and a great idea: the nonsensical text you decode ends up helping public domain book scanning projects.
But lately, we've been getting a steady stream of complaints that it is not working or is unsolvable. Last night I tried out the contact form and was surprised that in the first ten images presented to me (keep hitting the little refresh button, the top of the three buttons on the control), at least half were totally undecipherable.
Here's an actual screenshot of one I saw this morning. The first word is impossible to decipher. My question is, has ReCAPTCHA had such success that all we're left with is the really, really bad book scans?
Subscribe to our newsletter.
Be the first to know - subscribe today




